《Cognitive Electronic Warfare An Artificial Intelligence Approach》读书笔记(三)——机器学习入门
《Cognitive Electronic Warfare An Artificial Intelligence Approach》第三章的读书笔记。
目录
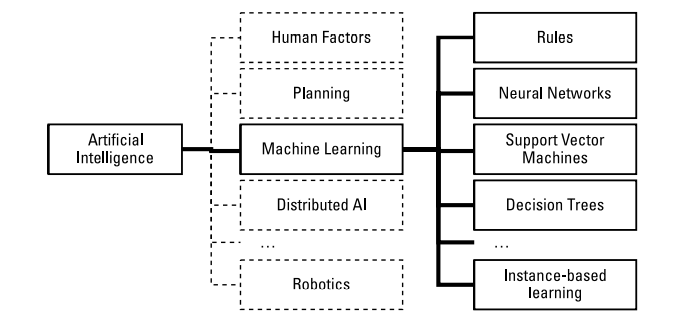
人工智能是计算机科学中的一个领域,取材于数学、工程和神经科学。机器学习(ML)只是众多子领域中的一个子领域,而人工神经网络(ANN)则是ML中分支中的一个。
“人工智能”不是“深度学习”的同义词。
$$AI⊃ML⊃DL$$
认知电子战技术利用机器学习对频谱进行建模,并学习如何有效地规划和优化。如果没有这种能力,电子战系统将无法处理新的发射源。
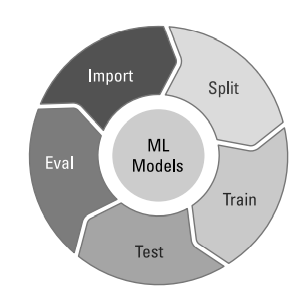
机器学习算法使用经验数据来学习空间模型。步骤如图:
机器学习算法通常分为有监督和无监督两种。是否有监督(supervised),就看输入数据是否有标签(label)。输入数据有标签,则为有监督学习;无标签则为无监督学习。
有监督学习中,因为输入和输出已知,意味着输入和输出之间有一个关系 $f : X → Y$,监督学习算法就是要发现和总结这种“关系”。
无监督学习是指对无标签数据的一类学习算法。因为没有标签信息,意味着需要从数据集中发现和总结模式或者结构。
半监督学习方法(Semi-supervised)有少量的标记样本和许多未标记的样本。
1. 常用机器学习算法
1.1支持向量机(SVM)
支持向量机是一类最大似然方法,用于聚类、分类、回归和异常值检测。支持向量机具有很高的聚类性能,特别是对于复杂的非线性关系和可用训练数据有限的情况。
支持向量机算法的决策函数中使用训练数据点的子集(称为支持向量(support vectors))。每个支持向量机构造一个决策函数,用于估计决策边界,即所谓的最大边际超平面(maximum-margin hyperplane),以及该超平面周围可接受的硬边界或软边界。支持向量是边界上的样本,如图3所示:
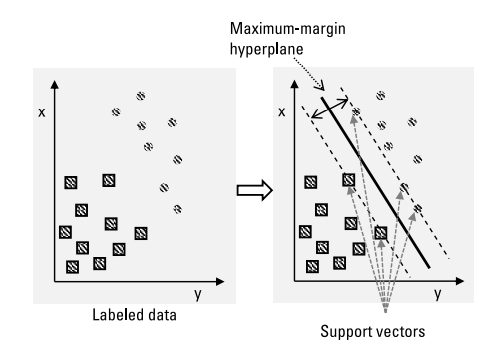
支持向量机通过使用核函数(kernel functions)完成非线性分类,将其输入映射到高维特征空间。
1.2 人工神经网络(ANN)
人工神经网络算法模拟神经元及其相互连接,以复制大脑的学习方式。反向传播算法实现了多层网络的训练:通过修改每个节点的权重来将误差项反向分布到各层。
ANN由输入层、隐藏层和输出层组成,层数是指网络的深度。现代的人工神经网络通常有很多层,因此被称深度网络(DeepNets)。DeepNets可以发现人类无法提取的复杂模式或潜在特征。
常见的DeepNet架构:
• 卷积神经网络(CNN)。典型的CNN由三种类型的层组成:卷积层、池化层和全连接层。卷积层通过卷积操作对输入图像进行降维和特征抽取。池化层简化了数据处理,缩减模型大小并降低过拟合。全连接层将一层中的每个神经元连接到下一层中的每个神经元,起到将学到的“分布式特征表示”映射到样本标记空间的作用。
• 递归神经网络(RNN)$^*$属于一类用于处理序列数据的神经网络。RNN具有反馈连接,通过保存存储器的内部状态来保留其输入数据的时间特性。
• 时态CNN处理与序列相关、与时间相关和与记忆相关的深度学习,有替代RNN的趋势。
• 自编码器学习,使用高效的数据编码并构建模型。自编码器试图从简化的编码中生成尽可能接近其原始输入的表示,能有效地学习消除噪声,经常用作异常检测器。
• Siamese神经网络在多个网络上使用相同的权重,而在不同的输入数据上进行训练。与其他方法相比,它们需要更少的训练数据。
• Kohonen网络,也称为自组织映射(SOM),产生输入空间的低维表示,用于降维和可视化。
• 生成性对抗性网络(GAN)是由两个相互竞争的神经网络组成的系统,每个神经网络都试图提高预测的准确性。生成网络的目标是愚弄判别网络。GAN通常用于创建合成数据。
模型评估自身置信度的能力很重要。
2. 组合方法(ensemble methods)
使用多个分类器可以提高预测精度,
常见的组合方法包括装袋算法(bagging)$^*$、提升方法(Boosting)和贝叶斯模型平均。装袋算法给组合中的每个模型都赋予了同等的权重,Boosting通过训练每个新模型来强调以前模型错误分类的训练实例,从而增量地构建组合,贝叶斯模型平均使用基于每个模型的后验概率的权重加权。
3. 混合机器学习(Hybrid ML)
符号人工智能(Symbolic AI)操作人类可读的符号,而非符合人工智能操作原始数据。决策树在本质上是非符号的,而DeepNet通常是符号性的。
混合算法将两者结合起来,利用符号知识构造特征,缩小搜索空间,提高搜索效率,对得到的模型进行解释,也被称为基于知识的机器学习或神经符号人工智能。
混合方法本质上“引导”了学习过程。分析模型提供了对结果有根据的猜测,经验数据改进了预测以与观察到的结果相匹配。混合方法使学习系统即使在没有训练数据的情况下也能工作。
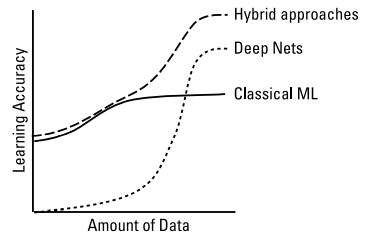
DeepNets识别数据中的潜在特征,而经典的机器学习方法依赖于表面的特征。
4. 开集分类(Open-Set Classification)
开集分类技术在初始模型被训练之后,在分类过程中创建新的类。这可以用来处理分类过程中遇到的未知数据。
在电子战任务中,任务过程中会遇到新的发射器,系统设计必须有从一两个例子中学习新模型的技术。
5.泛化与元学习(Generalization and Meta-learning)
泛化指的是模型能够适当地适应新的、以前未见过的数据,这些数据来自与用于创建模型的分布相同的分布。过度拟合意味着模型捕获训练数据太好,因此不能很好地处理新数据,而拟合不足则不能很好地捕获训练数据。良好的泛化意味着在不足和过度拟合数据之间找到正确的权衡。
元学习,是通过调整控制算法如何工作的超参数来控制过拟合和欠拟合。每个算法都有自己的超参数,例如决策树调整MaxDepth和MinSamples,而支持向量机调整$C$和$γ$(错误分类代价和单个数据的影响),DeepNet可能会使用提前停止(early stopping)和激活丢弃(activation dropout)$^*$。
2和3中提到的组合方法和混合方法也有利于防止过拟合和欠拟合。
6. 算法权衡
选择算法时需要解决的问题:
| 因素 | 需要考虑的问题 |
|---|---|
| 任务 | 了解环境吗/预测事件/控制行动/适应环境 |
| 数据 | 有多少培训数据可用(任务前和任务中)?有无标签?数据是否部分可见(即特征是否会丢失)?先验模型可以计算出哪些特征?训练后数据是否已更改? |
| 目标 | 解决方案必须有多精确?解决速度有无要求?解决方案是否需要向电子战指挥官做解释?是否需要可扩展到其他环境?哪些安全因素很重要? |
| 制约因素 | 必须满足哪些硬件要求?提供哪些算力(CPU、GPU、FPGA、自定义ASIC)?模型和数据有多少可用存储空间? |
机器学习算法设计经验:
• 在预测未来时,较大的复杂模型往往更准确地捕捉到绩效表面。在试图解释时,越小越简洁的模型越好。
• 当训练实例数量有限时,而经典的机器学习方法可能更有用。当训练实例数量多,训练时间充裕时,DeepNets可以更好发挥作用。



